In this note, we will introduce linearity of expectation for discrete random variables, how it’s used, why it’s useful, and very important subtleties. Along the way, we’ll prove a few useful things you might see in computer science.
We will assume you possess basic knowledge on what a discrete random variable is. Nothing formal here, we won’t be fully using the axiomatic method here but we’ll at least give a little formalism here because it will be useful to see things in this new light. Just bear in mind we won’t be going 100% formal, but just a taster of how to be a little more well-founded in what we do.
Introduction
You should think random variable as a variable that takes on potentially more than one value (it could also be just one value but that’s not very random nor interesting, is it?).
So has a set of values that it can take on, think of this as the set of possible events . Furthermore, for each value , we want to associate with it a value . You can now see this as a function . There are a few more requirements about these values.
- , .
In fact, we use as notation for .
Did you notice we basically just called it a function? Here’s the idea, we have some kind of phenomenon in real life we wish to model, but there’s some degree of uncertainty we have about that phenomenon. For example, something like “Which face of a dice will be on the top?” after we roll it. We would like to assign each outcome individually with a number in . What kind of number? Well it has to satisfy the constraints laid out above. For example, if we know the dice is “fair”, to model that dice using our mathematical objects we would say . If the dice was loaded and unfair instead we might assign different values to each outcome.
Note
Now to be clear these are not axioms of probability, rather, these requirements actually follow from the actual axioms of probability which I will not show because it is rather complicated. But you may treat this as the foundation on which we will start. Like how it might feel to learn Python instead of C, where the low-level details have been done for you, and you’re here to think about higher level details.
Anyway, there’s always the abstract question of “what does it mean for a phenomenon to have some probability?“. There’s the whole Frequentist vs Bayesian debate (that’s a whole big can of worms). So I just want you to appreciate the fact that at a very abstract level: we are just assigning numbers from our set of events to real values that satisfy the constraints that I mentioned.
Now technically speaking, there’s one more thing I should mention: A random variable is not the same as its distribution. A distribution is basically the function that satisfies the properties I mentioned. A random variable needs to take a distribution. Think of a variable as an instance. You could have two random variables that are identically distributed (they have the same function but potentially different outcomes). We will say two random variables are identically distributed if they have the same distribution function .
For example, if we had 2 perfect copies of the same fair, perfect, independent coin, then we could say there’s two random variables that both have the same distribution where .
Lastly, we will call a random variable discrete, if the event set is discrete.
Expected Value of a Random Variable
So given a discrete random variable , one thing we might want to ask is “What is the expected value?“. We will use to denote this value. First of all, the interesting thing about the expected value is that we can prove (as a separate theorem) that if we took trials of measuring , you can think of this as where they are all identically distributed as and all fully independent of each other, and we measured the value then this will converge to as . So here, we care about random variables that take on values in . i.e. the event set of are values we can add and divide.
Does this mean is most likely to take on value ? No. But nonetheless it tells us that if we are happy with many trials of , the “average value” that we will see, should be close to .
The definition of the expectation of a random variable is given as:
Now, there are other possible and equivalent formulations (shown as theorems) but we’ll stick with this one. Also, perhaps it’s pretty intuitive why this is the right definition. For example, we expect to see value , about fraction of the time.
So for example, if we let a coin be such that , and , then the expected value .
As another example, a dice with uniform probability of taking values will yield .
Conditioning Random Variables
Now if all we had to study was single random variables, this would not be so interesting. Let’s consider the following scenario: We have a bag that has 5 balls with the following values: .
And we want to draw two balls without replacement, and output their values. There’s two ways we model this:
Method 1: Directly creating a single random variable.
One way is to make a single random variable that takes on of possible values: , like so:
- . Either take the -ball first, then either of the -balls, or the other way around.
- . You have to take both of the -balls.
- . Either take the -ball first, then either of the -balls, or the other way around.
- . Either take one of the -balls first, then either of the -balls, or the other way around.
- . You have to take both of the -balls.
Then from this you can also do stuff like find .
Method 2: Creating two random variables instead.
We can instead create two random variables that models the first draw, and that models the second. However, there are very important subtleties that crop up in linearity of expectation later on, so pay some attention here.
’s distribution looks like this:
But what about ? To be clear we cannot just say that ‘s distribution is the same as . In some sense, because ‘s outcome depends on . To be clear, we want to figure out what are.
Now, . Think of this as saying: The probability that takes value is the sum of the probability of all the possible cases of what takes.
If that is not so convincing, you can think of it the following way:
Which is to say, either is with some probability, then conditioned on that probability, takes with some probability (accounting for the fact that the first ball drawn was ). So filling in these values, we get it to be:
Now isn’t that curious? Somehow it’s the same value. Indeed if you worked this out for , you get:
Also, works in similar way. Crazy isn’t it? Why is identically distributed to ?
Question
What? I don’t get it. Why does look like this? Okay, I need you to think in the following way: We drew two balls without replacement, let’s call it , . But then we threw the first ball away and only looked at the second ball . It’s a little trippy but this actually has the same distribution if we drew two balls without replacement, and then threw away the second ball and only looked at the first ball .
In general for any distribution here’s the idea (let’s just do it for 2 draws without replacement): Let be a set of items , with frequencies . Let . is basically the total number of items.
For example, with balls , then , and , , and . Then .
Okay we first think to note: Let be the first draw from the set based on their frequencies. Then . Let’s consider sets where . I.e. There are at least items to draw or else we cannot make a second draw in the first place.
The question is what is . So in general:
That looks suspiciously like innit?
Explanation
Line 1 follows from Bayes’ theorem.
Line 2 from splitting the sum based on whether or not. We need to treat them differently.
Line 3 follows from the fact that given , there are copies of remaining, and the total is reduced down to .
Line 3 also follows from the fact that given where , there are still copies of remaining, and the total is reduced down to .
Line 4 just factors out the portions independent of .
Line 5 follows from the fact we’re adding up all the frequencies except so this is just the total without , or .
Line 6 onwards is just basic algebra.
Now to be very clear: and are not independent. Why? but . So , which is enough to argue that and are not independent.
Linearity of Expectation
Okay, given what we know from the previous section, we can now ask the following question: What is the expected value of the sum of the values of the two balls drawn? Well if you used method 1 from above, then you’d just have to do .
Or you could use method 2, and now you know that and are identically distributed, so you really just need to find . This happens to be a lot simpler: . Then, if we believe in linearity of expectations, we know that
What if the two draws were with replacement?
Well then I hope you know that definitely and are identically distributed. And furthermore, if the draws were with replacement (and both draws were done the same way), then and are independent. So the above equation still holds!
Proof of Linearity of Expectation
Again, we want to show something like given two random variables , that may or may not be independent, .
So why does it not matter if two variables are independent or not? Let’s see:
Now because are not necessarily independent, we cannot write . However, let me split the sum into two summations first.
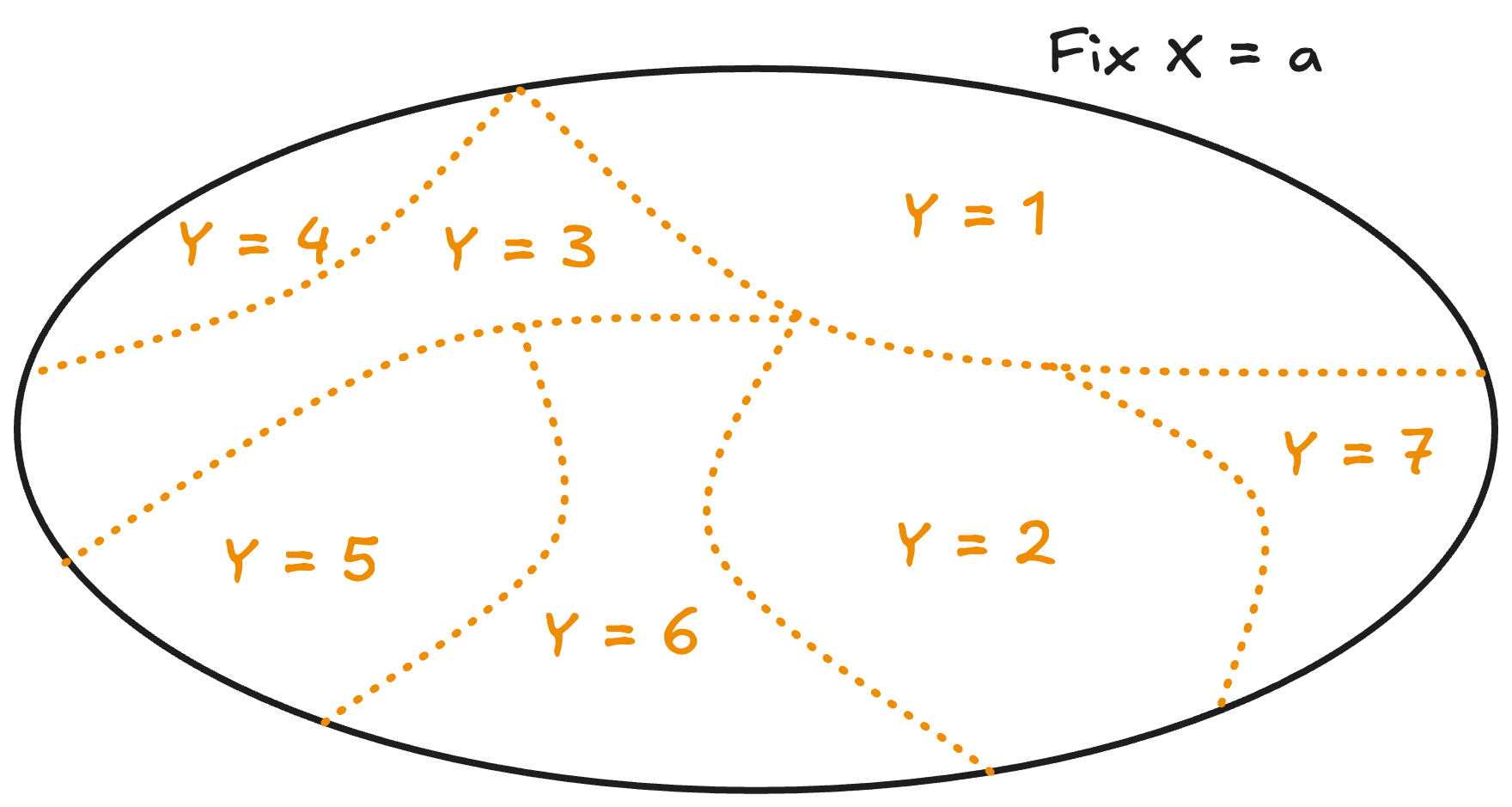
Now there’s two parts we need to handle, but they’re handled with the same idea: If we fix , and said , then summing across all , where we vary the value , then the value is actually just . Think of it this way, can be broken up into disjoint parts and so on. If we added them all back up, we just get again. Below is an example of this intuition with taking on possible values:
So because of that:
and likewise:
which means the original two parts just becomes .
Where do we use Linearity of Expectations in CS?
Many places! I will show you a few things that you might see in CS2040S, and CS3230.
The Classic Hat Check Problem
Let’s say there are people, each person has a unique label from . They each also have a unique hat. The person basically has the hat. They enter the restaurant to dine, and as they leave, they each take a remaining hat uniformly at random. Effectively, you can also think of this as the hats being permuted uniformly at random. I.e. put a random permutation function . Then the person gets the hat.
How many people do we expect to get their hat back? Going through permutations is a big pain if you want to do the following:
In particular, if we let be the random variable that counts how many people get their hat back, to get you’d effectively kind of have to use generalised principle of inclusion exclusion.
There’s a slightly easier way if you know that since takes on value in we can also use:
and this makes the task slightly easier, but still a little tricky because you’ll have a lot of factorials that you’ll need to simplify.
So here’s the simplest possible way (a technique you’ll see again in the future):
Let be a random variable that is if , and otherwise. So think of as basically adding to a counter when it’s happy (i.e. when the person gets their hat back).
Now to be clear, between any , and are definitely correlated. After all, you’d expect to be more likely to be when is also . The probability of the outcomes of change when we know what is. That said, there’s nothing wrong with writing:
Now literally counts the number of people who got their hat back. E.g. when all are , no one got their hat back, so . So now what is ? Well that’s just:
So why’s this so significant? Because it tells us that instead of worrying about the correlations, we can get the expected values separately. Which is a huge load of work off our shoulders. Indeed, fix any , let’s look at what happens:
Which means that the expected value of is just the probability that it is .
So what is the probability that it is ? Well, there are permutations, and there are many permutations where we insist that . So the probability is . So coming back to our original working:
So regardless of the number of people, in expectation only person will get their hat back.
Quicksort analysis
So you’ve probably learned quicksort by now. As a quick refresher, let’s see the algorithm again:
function quicksort(xs) {
// Let k = length of xs
// O(1)
if (is_null(xs) || is_null(tail(xs))) {
return xs;
} else {
// O(k)
const pivot_index = math_floor(math_random() * length(xs));
// let i = value of pivot_index
// O(i)
const pivot = list_ref(xs, pivot_index);
// O(k)
const lower = filter(x => x < pivot, xs);
// let l = length of lower
// O(k)
const pivots = filter(x => x === pivot, xs);
// let p = length of pivots
// O(k)
const higher = filter(x => x > pivot, xs);
// let h = length of higher
// T(l)
const sorted_lower = quicksort(lower);
// T(h)
const sorted_higher = quicksort(higher);
// O(p + h)
return append(append(sorted_lower, pivots), sorted_higher);
}
}Now you might have been taught that this runs in time because in the worst case, the array might because the every time we recurse the list might only be of size smaller or something along those lines.
But what if we always randomly picked a pivot to use in the partitioning step? What happens then?
We can actually show the expected runtime is . You can imagine how using:
would be tricky, where is the running time of quicksort. So instead we will note the following:
The runtime of quicksort is at most where is the number of comparisons made by the algorithm. Why? Because the algorithm makes time steps for either comparing or swapping. In fact, swapping only happens when a comparion against the pivot happens. So really, the runtime of quicksort is bounded by the number of comparisons we’re making.
So how do we bound ? Well it’s a random variable now, because the number of comparisons depends on what is the exact input we were given, and it has been randomly permuted before the function was called.
So we’re going to define as a sum of other random variables, and again let LoE take over. So what should we do?
Here’s an idea, given some input list, , consider its sorted order . It’s true that the run of the algorithm looks at . But we can correspond them to the elements in the sorted order for the sake of analysis.
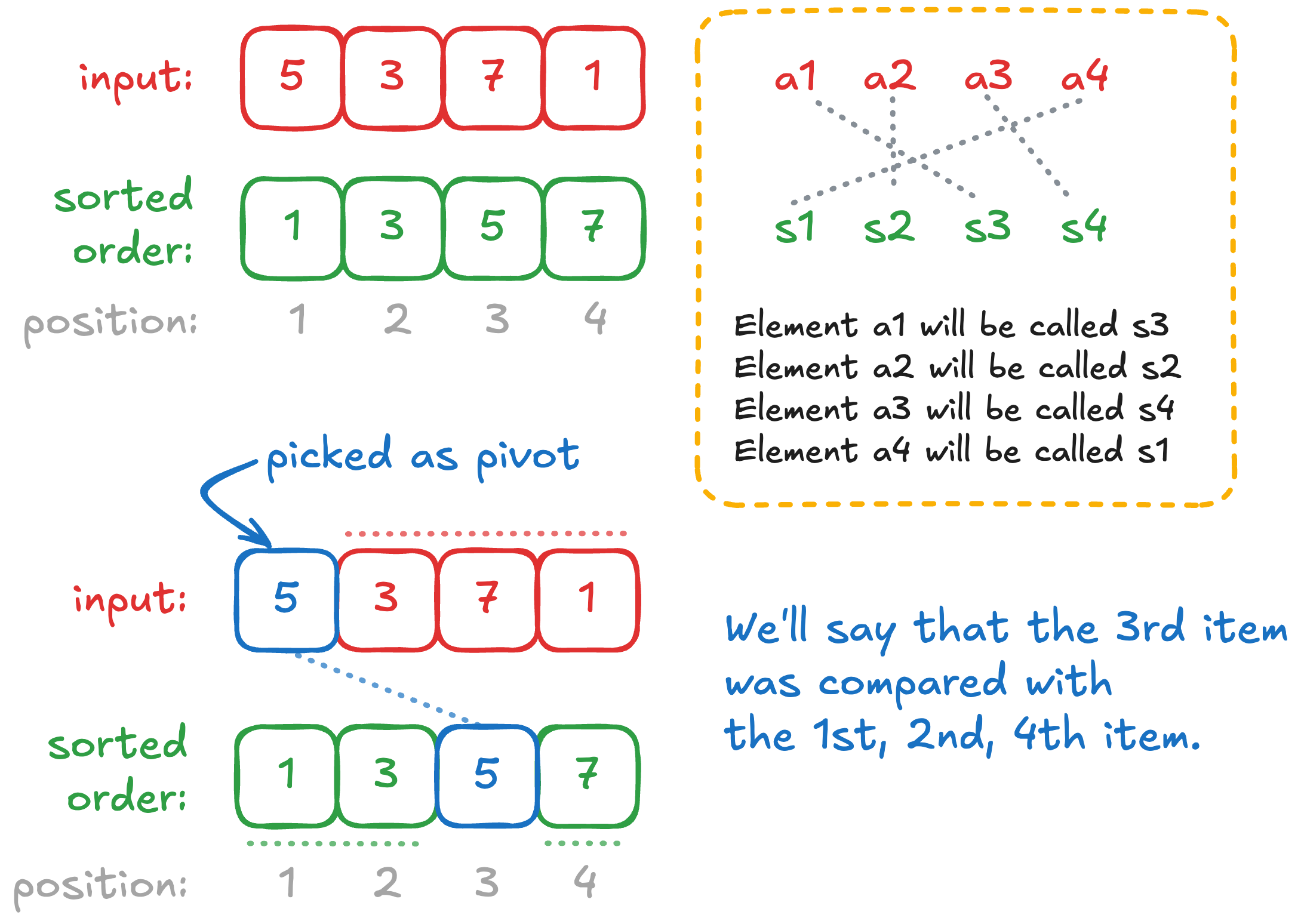
For example, if the input was , if we pick the element as the pivot, we’re actually going to think of this as picking which happens to be , so we’ll think of this as taking the item as the pivot (instead of the ). There’s going to be a reason for this.
Let if during the run of the algorithm, was compared with . So in the example above, . Also being compared is a symmetric relation, so for example . Otherwise, if are never compared, then .
Let’s think about this a little bit. Let’s say we knew for a fact that . What can we now say about the pivot selection? Remember the only comparisons happen due to the partitioning function, and swaps only happen when the comparisons trigger it. So either element or element was selected to be a pivot at some point in the execution of quicksort.
Bear in mind the moment something was selected as a pivot once, it will never be selected as a pivot again. Furthermore, a pivot actually partitions the array. E.g. if element was selected as a pivot first. Then we know that element and will never be compared again after that.
Okay, so what we want to say is:
literally counts the total number of comparisons made during quicksort. Because it literally iterates between all the distinct pairs . Now:
And again, since is only either or :
So combining with the above, we get:
Okay so again, what’s the probability that ? Well it’s the probability that and was compared. So let’s think about how that might happen.
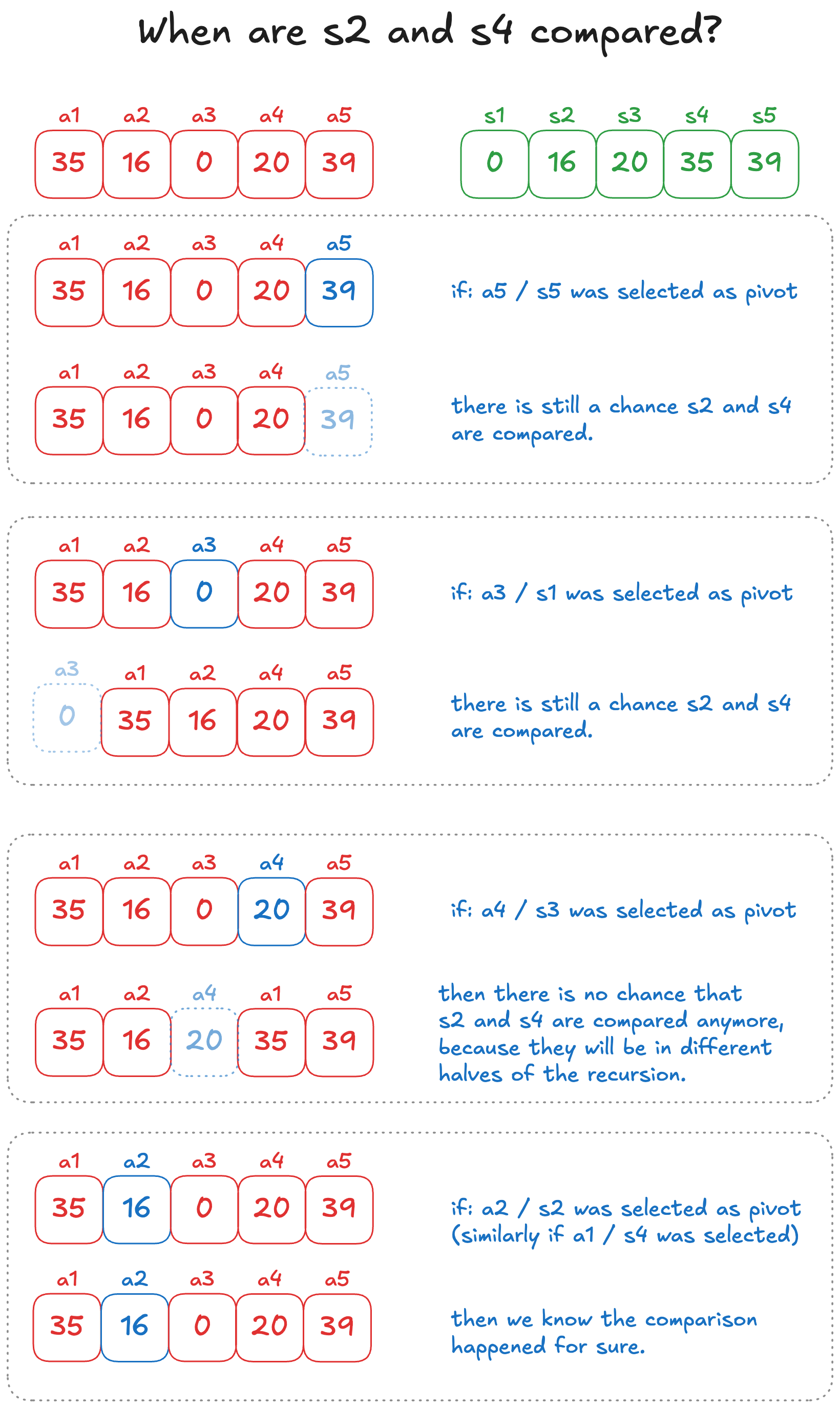
Here’s an example where the array (or sub-array) we wish to sort has 5 elements. For example if we care about whether and were compared, there’s actually possible cases:
- Either at some point in the algorithm we picked element or as the pivot. In which case, it’s inconclusive as to whether or not or was taken.
- Or at some point we picked or as the pivot. In which case we know for a fact they were compared.
- Or at some point we picked was picked as the pivot. In which case we know for a fact that and will never be compared.
So in general:
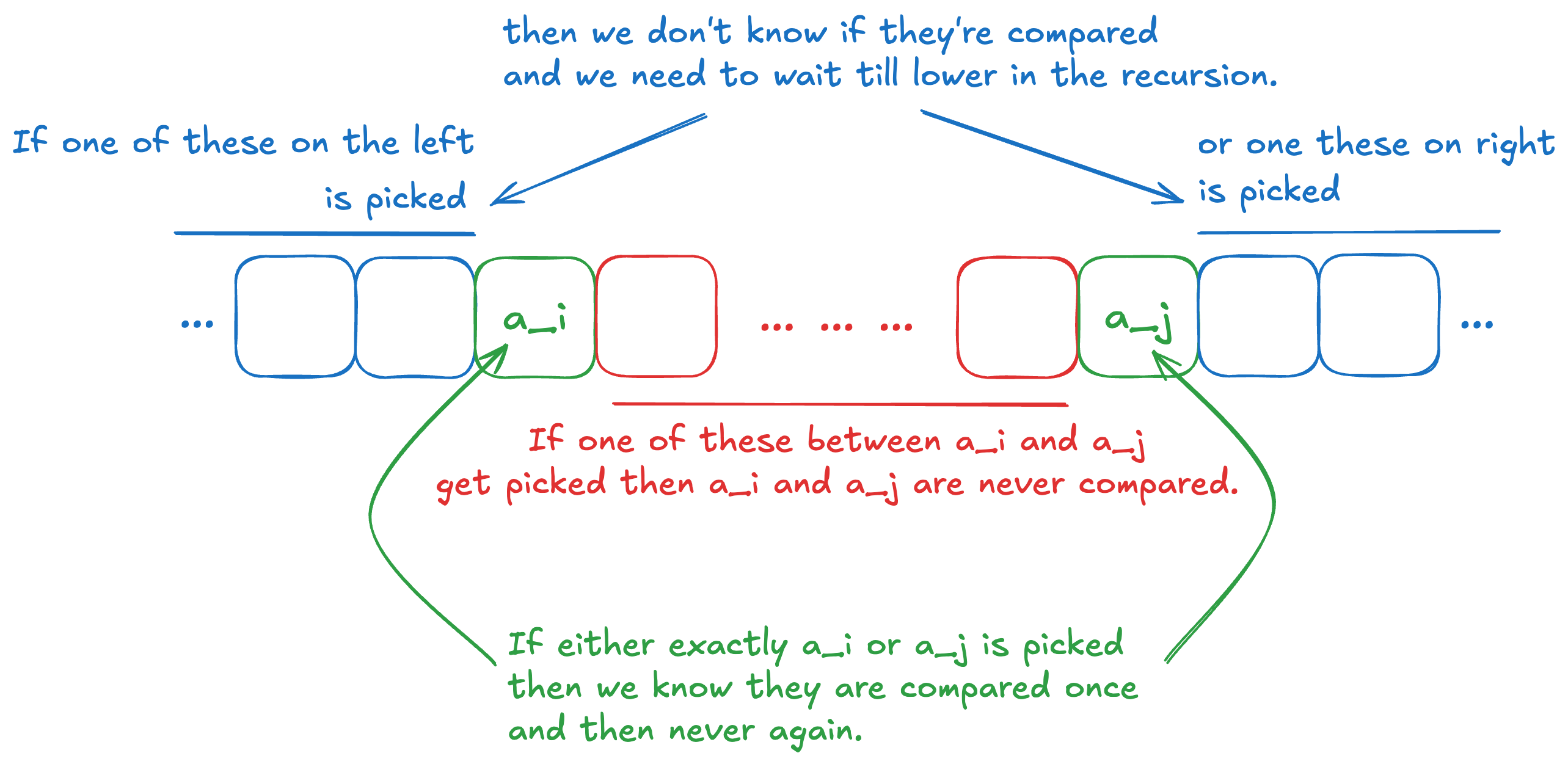
So for some two elements and , first of all note we don’t care if anything before or after was chosen as pivots at any point in the execution. What we care about is in the sequence was chosen as pivots. If or was chosen as a pivot, then . Otherwise, one of was chosen. In which case, .
Since pivots are chosen randomly, the probability that either or is chosen, is just because there are valid choices, and the are possible choices including elements from to (inclusive).
Now to finish it all off, we get that:
where on the first line we use the fact that we’re summing , so we might as well just change the variable to such that it ranges from to in the denominator. Then summing from to gives us fewer positive terms than if we just summed from to , so the next line is an upper bound. Now, to see that it is , we use the following idea:
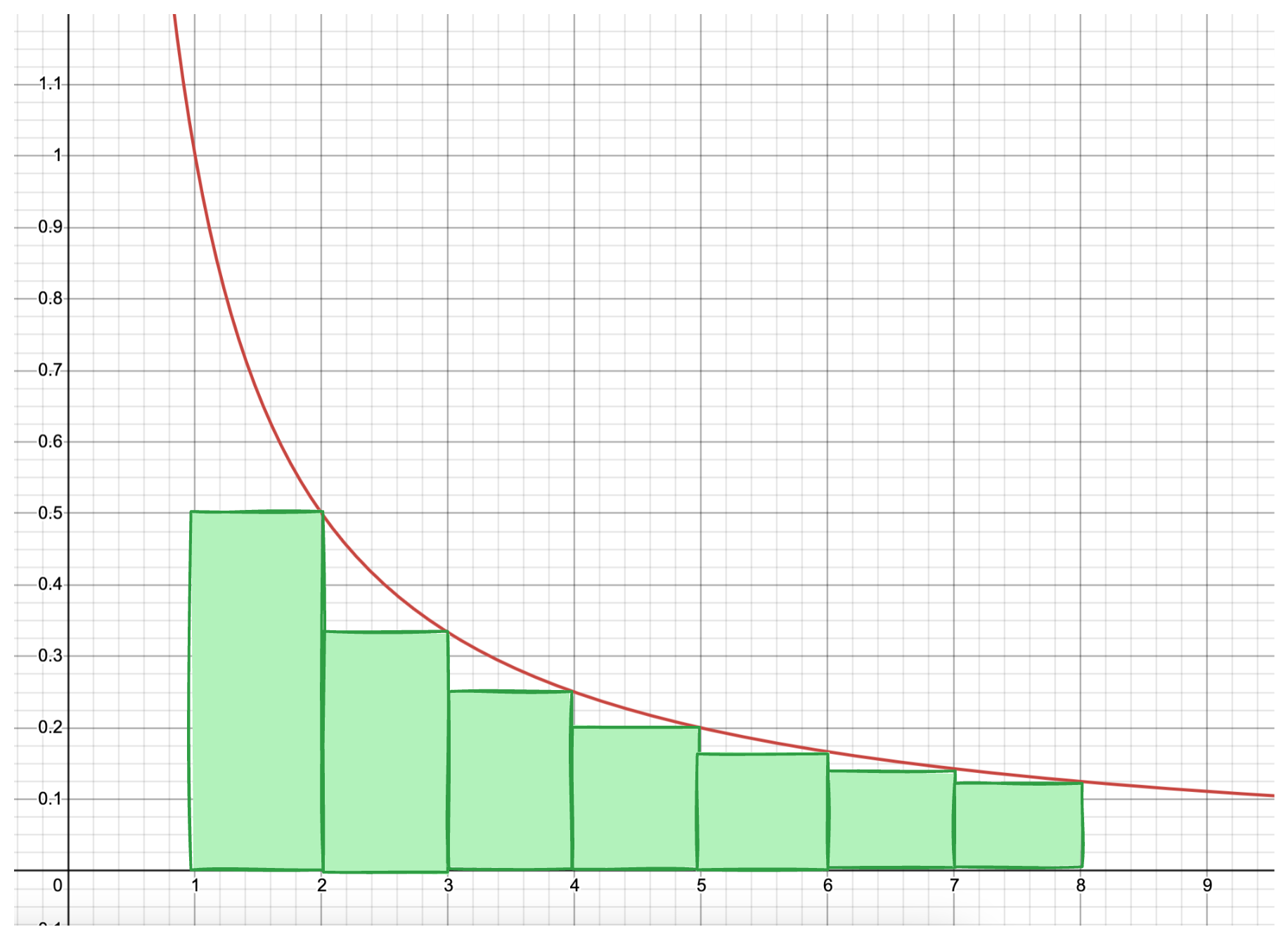
The red line plots the function. So the area under the curve is an over-approximation of adding for values from up to . Thus the integral of from to is at most .
So! We’ve shown that the expected running time of randomised quicksort is (or , if you know that you can change bases between and with a constant factor multiplication).